추천 시스템 평가하기
추천 시스템 평가하기
최근 평소 보지 못했던 데이터셋 분리 방식을 접했습니다.
train.csv # 트레이닝 데이터셋
validation_tr.csv # 검증 데이터셋 내의 학습 데이터
validation_te.csv # 검증 데이터셋 내의 테스트 데이터
test_tr.csv # 테스트 데이터셋 내의 학습 데이터
test_te.csv # 테스트 데이터넷 내의 학습 데이터
참고링크) “Enhancing VAEs for Collaborative Filtering” Github 저장소 https://github.com/psywaves/EVCF/tree/master/datasets/ML_20m
검증 데이터셋과 테스트 데이터셋에서 다시 데이터셋을 분리하는 이유가 궁금하기도 했고, 추천 시스템의 평가와 관련해서 놓치고 있는 부분도 있을 것이라는 생각이 들었습니다. 이번 기회에 Kim Falk의
추천 시스템의 검증 프로세스
추천 시스템을 검증하는 가장 확실한 방법은 실제 서비스를 제공하는 라이브 환경에서 적용하는 것입니다. 하지만 라이브 환경에 바로 적용했을 때의 문제점은 추천 알고리즘이 사용자 경험을 해친다면 사용자를 잃을 수 있다는 것입니다. 그래서 추천 시스템을 평가하기 위해서는 아래의 단계를 거치는 것이 적절합니다.
1) 작은 데이터셋에 대해 알고리즘 검증
5명의 사용자와 10개의 아이템 정도의 데이터셋으로 알고리즘이 잘 동작하는지 확인하는 것이 우선입니다. 작은 데이터셋에 대해 잘 동작하는 것을 확인한 다음, 알고리즘을 제대로 구현하는 것이 좋습니다.
2) 회귀 테스트(Regression Test)
데이터가 추가되고 코드의 변경이 있을 때마다 회귀 테스트를 계속해서 진행하는 것이 적절합니다. 알고리즘이 잘 동작한다는 것이 검증되면 오프라인 실험으로 넘어가도 좋습니다.
3) 오프라인 실험(Offline Experiments)
오프라인 실험은 보유하고 있는 데이터셋을 학습 데이터와 테스트 데이터로 분리하여 추천 시스템이 잘 동작하는지를 확인하는 방법입니다. 추천 모델을 정확히 평가하기 위해서는 실제 사용자의 선호도를 나타내는 “ground truth” 데이터에 접근할 수 있어야 합니다. 하지만 이를 알 수 없기 때문에 현재 보유하고 있는 데이터에 나타나는 사용자와 아이템의 상호작용이 “ground truth”이고, 사용자의 선호도를 잘 대표하는 것으로 가정합니다.
4) 사용자 분석(User Study)
작은 수의 참가자들을 대상으로 추천 알고리즘의 성능을 평가하는 방법입니다. 이 단계에서 문제가 없다면 일부 사용자들을 대상으로 출시하는 것도 좋습니다.
5) 온라인 실험(Online Experiments)
작은 수의 사용자들을 대상으로 긍정적인 피드백을 받았다면 라이브 환경에서 추천 시스템을 적용한 다음, 일부 사용자들을 대상으로 A/B 테스트를 진행해볼 수 있을 것입니다.
단계를 넘어갈수록 시간과 비용은 올라갑니다. 온라인 실험 이전 단계들의 목적은 더 적은 시간과 낮은 비용을 투입하여 사전 검증을 하는데 있습니다. 이 점을 유의하여 오프라인 실험 시 데이터셋이 서비스 환경의 사용자들의 상호작용을 잘 반영하는지 확인하고, 사용자 분석의 참가자들은 라이브 환경의 사용자들을 잘 대표하는지 확인한다면 더욱 적절한 검증이 될 것이라 생각합니다.
데이터셋 분리 시 시간 축 고려하기
오프라인 실험(Offline Experiments)에서 데이터셋을 분리하는 방법은 크게 3가지입니다.
- 무작위로 분리(random splitting)
- 특정 시점을 기준으로 분리(split by time)
- 사용자를 기준으로 분리(split by user)
이 중 무작위로 데이터셋을 분리할 경우 문제점은 시간 축을 고려하지 못한다는 것입니다. 추천은 과거 사용자(user)와 아이템(item)의 상호작용 이력(ex: 상품 장바구니 담기, 상품 구매)을 바탕으로 사용자가 아직 접하지 못한 상품의 선호도를 예측하는 것이기도 합니다. 그러므로 사용자의 상호작용한 아이템 중 일부를 그저 제외하여 테스트 데이터로 사용하는 것보다는 시간 축을 기준으로 과거 이력 데이터를 활용하여 아직 접하지 않은 상품의 선호도를 예측할 수 있도록 분리하는 것이 합리적입니다.
Split by time
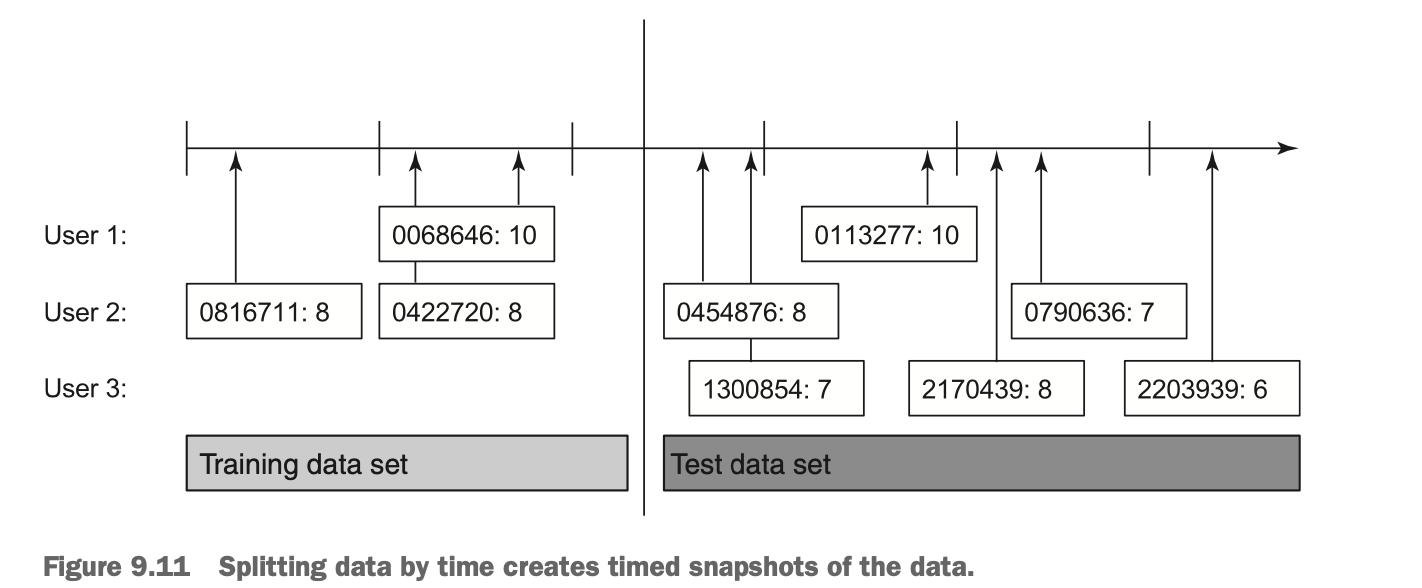 “Practical Recommender Systems by Kim Falk” Chapter9의 9.11 그림
“Practical Recommender Systems by Kim Falk” Chapter9의 9.11 그림
시간 축을 기준으로 데이터셋을 분리하는 것은 데이터셋에 있는 시간(timestamp) 데이터를 활용하여 특정 시점 이전의 데이터는 학습 데이터, 특정 시점 이후의 데이터는 테스트 데이터로 취급하는 것을 말합니다. 이 때 문제점은 위 그림의 User 3처럼 테스트 데이터에만 포함되는 사용자가 있을 수 있다는 것입니다. 이 때 새로운 사용자(cold user)를 평가할 수 있는 기회로 볼 수도 있지만 학습 데이터에 없는 사용자를 테스트한다는 것은 알고리즘의 성능을 확인하는 데 있어 적합하지 않습니다. 그러므로 특정 시점을 기준으로 데이터셋을 분리할 때는 User 3과 같은 학습 데이터에 포함되지 않은 사용자들은 제외하는 것이 적절합니다.
Split by user
사용자를 기준으로 데이터셋을 분리하는 방법은 일부 사용자들을 학습 데이터에 넣고, 나머지 사용자들을 테스트 데이터에 넣는 방식이 아닙니다. 개별 사용자에 대해 첫 번째 n개의 상호작용 또는 평점 데이터를 학습 데이터셋에, 나머지를 테스트 데이터셋에 포함시키는 방식입니다.
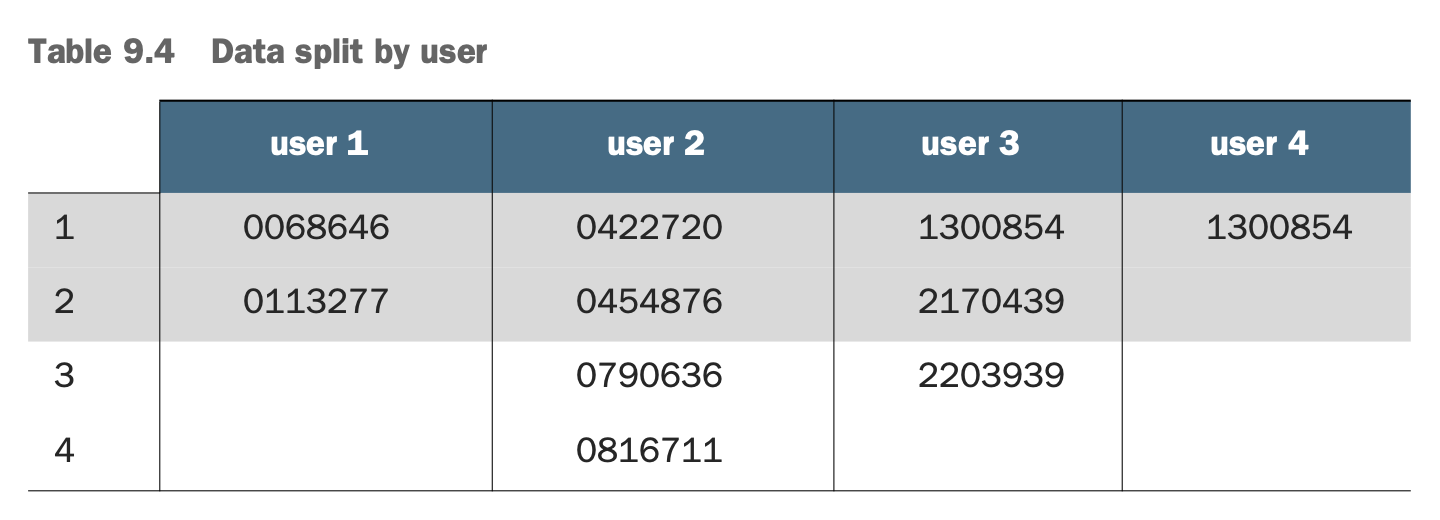 “Practical Recommender Systems by Kim Falk” Chapter9의 9.4 테이블
“Practical Recommender Systems by Kim Falk” Chapter9의 9.4 테이블
위 경우 User 1, User 4는 테스트 데이터셋에 데이터가 포함되지 않았습니다. 하지만 모든 사용자가 테스트 데이터셋에 포함되었고, 테스트 데이터셋에 학습 데이터에 없는 사용자는 없습니다.
위 방식들을 사용하면 시간 축을 고려하여 데이터셋을 분리할 수 있습니다. 참고로 시간 축을 기준으로 데이터셋을 분리하기 앞서 평점을 매긴 횟수 또는 아이템과의 상호작용 횟수를 기준으로 사용자를 제외합니다.
If you’ve many users with only a few ratings,
then it’s a bit harsh to penalize the recommender
if it can’t recommend something sensible to a user
that you basically don’t know anything about.
You’ll usually filter users away with only a small number of
interactions in your data.
Another problem is what to do if you’ve too much data.
In that case, you might need to try sampling.
“Practical Recommender Systems by Kim Falk” Chapter9의 HANDLING NEW USERS 섹션
그 이유는 사용자와 아이템의 상호작용이 너무 적으면, 추천 시스템이 알 수 있는 사용자의 정보가 거의 없다는 말이고, 그에 따라 사용자의 취향을 반영하는 개인화 추천을 하는 것이 어렵습니다. 또한, 데이터셋을 분리하는 관점에서도 학습 데이터와 테스트 데이터에 사용자가 모두 포함되기 위해서는 충분한 수의 상호작용이 필요합니다.
참고) microsoft/recommenders/examples/01_prepare_data/data_split.ipynb https://github.com/microsoft/recommenders/blob/main/examples/01_prepare_data/data_split.ipynb
3.3.2 Min-rating filter
A min-rating filter is applied to data before it is split
by using chronological splitter.
The reason of doing this is that, for multi-split,
there should be sufficient number of ratings for user/item in the data.
목적을 고려한 평가 방법 사용하기
평가는 ‘가치나 수준 따위를 평한다’는 의미가 있습니다. 여기서 수준이라는 말 앞에는 “목적 달성”이라는 말이 숨어있다고 생각합니다. 그래서 추천 시스템의 평가는 추천 시스템을 도입하는 목적, 추천 시스템을 어떻게 정의하는가, 어떤 비즈니스 도메인인가 등에 따라 달라질 수 있다고 생각합니다.
앞서 아래와 같이 검증 데이터셋과 테스트 데이터셋 내에서 데이터셋을 다시 분리하는 방식을 언급했습니다.
train.csv # 트레이닝 데이터셋
validation_tr.csv # 검증 데이터셋 내의 학습 데이터
validation_te.csv # 검증 데이터셋 내의 테스트 데이터
test_tr.csv # 테스트 데이터셋 내의 학습 데이터
test_te.csv # 테스트 데이터넷 내의 학습 데이터
“Collaborative Filtering: A Machine Learning Perspective by Benjamin Marlin”(https://people.cs.umass.edu/~marlin/research/thesis/cfmlp.pdf)에서 위 분리 방식의 이유를 알 수 있었습니다. “Collaborative Filtering: A Machine Learning Perspective”는 week generalization과 strong generalization에 대해 설명합니다. weak generalization은 학습 데이터에 포함된 사용자들에 대해 해당 사용자들이 아직 접하지 않은 아이템에 대한 선호도를 예측합니다. weak generalization의 문제점은 완전히 새로운 사용자에 대해 추천 알고리즘이 어떻게 동작하는지는 알 수 없다는 것입니다. 그래서 strong generalization은 학습 데이터셋에 포함되지 않은 새로운 사용자들의 선호도를 예측합니다.
위 분리 방식은 strong generalization을 위한 것입니다. 새로운 사용자들에 대해 모델의 성능을 확인하기 위해 검증 데이터셋과 테스트 데이터셋 내에서 한 번 더 데이터셋을 분리하는 것입니다. 평가의 목적에 따라 RMSE, Recall 등 다른 평가지표를 사용하는 것처럼, 평가 목적에 따라 다른 분리 방식도 달라지는 것입니다.
나가며
추천 시스템의 평가 지표 등 추천 시스템을 평가하기 위해 필요한 모든 부분을 세세히 언급하지는 않았습니다. 또, 추천 시스템이 이미 익숙한 분들에게는 너무 익숙한 내용이었을 것이라 생각합니다. 하지만 “Collaborative Filtering: A Machine Learning Perspective by Benjamin Marlin”을 참고하고, “Practical Recommender Systems” 책의 “Evaluating and testing your recommender” 부분을 학습하며 충분히 의미 있었던 부분도 있었습니다. 바로 추천 시스템을 어떻게 정의하고, 평가의 목적이 무엇인가에 따라 평가 방법은 달라진다는 것입니다. 상황에 따라 합리적인 방법을 선택하기 위한 생각이 필요하겠습니다.
긴 글 읽어주셔서 감사합니다. 부족한 글이니 댓글로 다양한 생각과 피드백 주시면 감사하겠습니다.
